Stable Diffusion: как запустить генератор изображений на своём компьютере
Сегодня облачные сервисы для генерации изображений, такие как Midjourney и DALL-E, уже стали обычными инструментами. Они рассчитаны на лёгкость использования и позволяют за несколько секунд создать иллюстрацию по текстовому запросу. Их механика работы максимально упрощена, но и настройки при этом ограничены.
Однако есть альтернативное решение: Stable Diffusion, гибкий инструмент, который можно развернуть локально у себя на компьютере и настроить под свои задачи. В статье расскажем, как работает Stable Diffusion, на что обратить внимание при установке и как получить качественный результат генерации.
Что такое Stable Diffusion
Stable Diffusion — это программа на основе ИИ, которая генерирует изображения с помощью диффузионных процессов. Её архитектура позволяет создавать иллюстрации в самых разных стилях, от мультяшных до фотореалистичных.
Но чем Stable Diffusion принципиально отличается от Midjourney и DALL-E? И зачем тратить время на её установку и настройку? Вот основные причины:
Свобода выбора и гибкость. Вы получаете полный контроль над процессом. Можно выбирать разные модели, экспериментировать с алгоритмами сэмплирования, настраивать стиль и качество изображений под конкретные задачи.
Бесплатно и без ожидания. Stable Diffusion — это проект с открытым исходным кодом. В отличие от облачных решений, здесь не придётся ждать очереди на сервере или платить за подписку. Единственное возможное ограничение — производительность «железа», на котором будет работать программа.
Лицензия на изображения. Зачастую облачные сервисы устанавливают ограничения на коммерческое использование или редактирование сгенерированных изображений. Во многих моделях Stable Diffusion таких ограничений нет, поэтому вы можете свободно использовать полученные иллюстрации при условии соблюдения лицензии конкретной модели.
Как происходит процесс генерации
Говоря простыми словами, Stable Diffusion формирует набор случайных пикселей и с каждым новым шагом «очищает» их от шума, создавая осмысленное изображение. Вот как это происходит:
1. На первом этапе модель создаёт зашумлённое поле. Оно служит отправной точкой для дальнейшего процесса.
2. Далее, шаг за шагом, начинается «очистка» от шума. Появляются цвета и узнаваемые объекты.
3. С каждым новым этапом генерация всё точнее соответствует описанию. На последнем шаге вы получаете готовое изображение.
 Шаги генерации изображения в Stable Diffusion по запросу «Cat on a sofa, white and gray fur»
Шаги генерации изображения в Stable Diffusion по запросу «Cat on a sofa, white and gray fur»
Алгоритм генерации можно условно разделить на несколько ключевых компонентов:
Текстовый энкодер — преобразует ваш запрос в эмбеддинг (массив чисел). Эмбеддинг служит как своеобразный шифр, сообщающий программе, что именно нужно отобразить.
U-Net — основной компонент, отвечающий за пошаговую «очистку». На каждом шаге он оценивает текущую версию изображения и анализирует, какие изменения нужно внести, чтобы оно лучше соответствовало запросу.
VAE (Variational Autoencoder) — преобразует латентное представление («черновик» изображения) в финальный результат. Для Stable Diffusion доступны различные версии VAE: одни лучше передают цвета и текстуры, а другие помогают сделать результат более реалистичным либо стилизованным.
Как развернуть Stable Diffusion на своём компьютере
Для эффективной работы Stable Diffusion требуется довольно производительное оборудование. Вот минимальные рекомендуемые характеристики:
Видеокарта: не менее 6 ГБ видеопамяти, оптимально — от 8 ГБ (например, NVIDIA RTX 2060, RTX 3060 или более новые модели).
Процессор: современный многоядерный CPU. Хотя основная нагрузка ложится на видеокарту, процессор участвует в подготовке и загрузке моделей.
Оперативная память: от 8–16 ГБ. Чем больше, тем лучше.
Свободное место на диске: от 10–30 ГБ. Желательно больше, чтобы разместить саму программу, модели и все необходимые дополнения.
Установка
Наиболее популярный и стабильный интерфейс для запуска Stable Diffusion — AUTOMATIC1111 Web UI. Он позволяет генерировать изображения прямо в браузере через удобный веб-интерфейс.
Для его корректной работы потребуется сначала установить Python и git. После этого можно скачать актуальную версию AUTOMATIC1111 из официального репозитория на GitHub и следовать пошаговой инструкции по установке. Весь процесс подробно описан в документации проекта.
Что делать, если у вас AMD
Владельцы видеокарт AMD могут столкнуться с трудностями, так как модели Stable Diffusion по умолчанию ориентированы на CUDA, технологию параллельных вычислений от NVIDIA. Для AMD существует аналог — ROCm, но его официальная поддержка ограничена.
Тем не менее, AUTOMATIC1111 можно развернуть и на AMD. Однако значительно проще и удобнее будет воспользоваться приложением AMUSE. Это графический лаунчер для ПК под управлением Windows. Он поддерживает использование различных моделей и предоставляет множество настроек и параметров (в профессиональном режиме).
Как создавать изображения по описанию
Основной режим использования Stable Diffusion — text2img. Здесь пользователь задаёт описание и устанавливает нужные параметры, а модель обрабатывает запрос и генерирует изображение.
Ниже — ключевые настройки, которые влияют на процесс генерации:
Prompt. Текстовое описание того, к чему должен стремиться Stable Diffusion при создании изображения. Запросы нужно составлять только на английском языке в виде ключевых слов и словосочетаний: естественная речь и длинные фразы здесь не подойдут.
Negative Prompt. Это обратное описание — то, от чего Stable Diffusion следует максимально отходить при генерации. Здесь работают те же правила: запрос только на английском языке по ключевым словам или фразам.
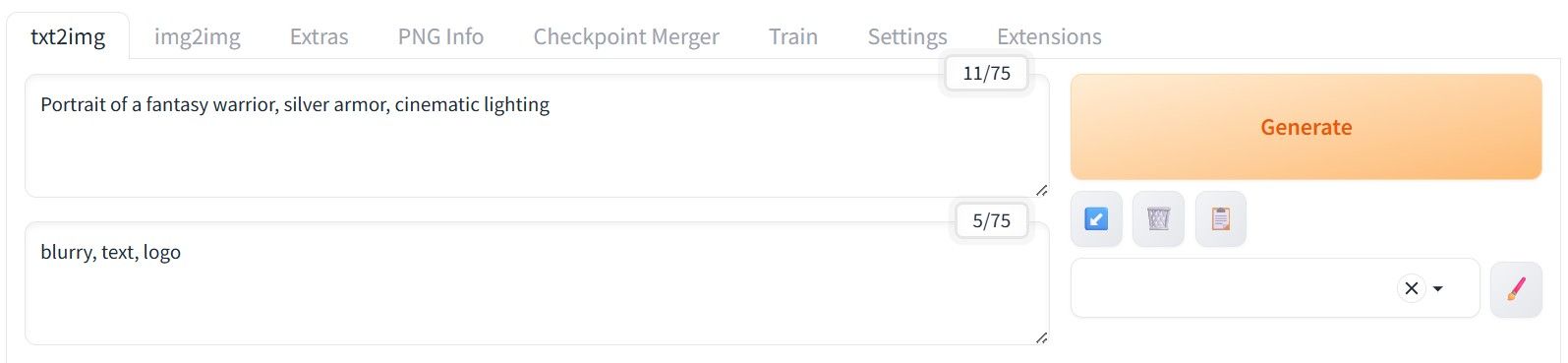 Пример запроса в AUTOMATIC1111. Сверху — Prompt, снизу — Negative Prompt
Пример запроса в AUTOMATIC1111. Сверху — Prompt, снизу — Negative Prompt
- Sampling Method, или просто сэмплер. Алгоритм, который управляет пошаговым превращением шума в готовое изображение. От выбранного сэмплера могут зависеть стиль и детализация, скорость генерации и необходимое число шагов для достижения лучшего результата.
Вот несколько популярных вариантов:
1. Euler a — быстрый и универсальный, подходит для небольшого количества шагов (от 20 до 30).
2. DPM++ 2M — предлагает хорошее качество деталей и стабильность. Хорошо подходит в том числе для большего количества шагов (например, от 30 до 50).
3. Heun — экспериментальный метод. Работает медленнее, но иногда позволяет получить интересные текстуры и необычный стиль.
4. DDIM — быстрый вариант, создаёт более гладкие детали, хорошо себя показывает при количестве шагов от 25 до 50.
 Примеры генерации по запросу «Portrait of a fantasy warrior, silver armor, cinematic lighting»
Примеры генерации по запросу «Portrait of a fantasy warrior, silver armor, cinematic lighting»
Это лишь основные варианты сэмплеров: в интерфейсе их доступно гораздо больше. Поэтому стоит экспериментировать и подбирать тот, который лучше всего вам подходит.
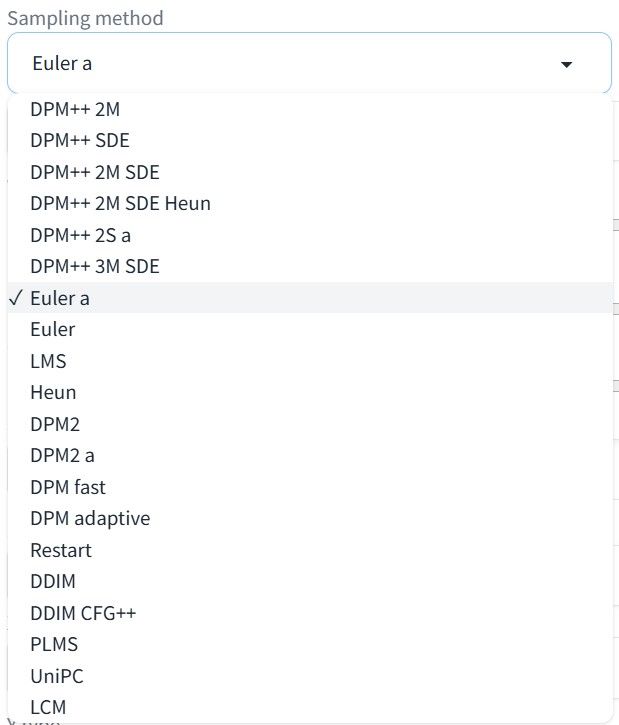 Пример списка сэмплеров в интерфейсе
Пример списка сэмплеров в интерфейсе
- Sampling Steps. Число шагов очистки изображения от шума. Чем больше шагов — тем выше детализация, но и генерация будет длиться дольше.
 Результаты генерации на разных шагах по запросу «Woman, curly hair, smiles at camera»
Результаты генерации на разных шагах по запросу «Woman, curly hair, smiles at camera»
- CFG Scale. Этот параметр определяет, насколько строго модель должна следовать описанию. Например, при низком значении (1–3) модель слабо учитывает запрос, а результат может быть абстрактным. Среднее значение (7–9) обеспечивает оптимальное соответствие запросу. Высокое значение (12+) даёт максимальную привязку к запросу, но возможны артефакты и неестественные детали.
 Генерация по запросу «Man in a hat, smiling, wine glass in right hand» с разными CFG
Генерация по запросу «Man in a hat, smiling, wine glass in right hand» с разными CFG
Width / Height. Ширина и высота итогового изображения в пикселях. Для максимального качества генерации лучше использовать размеры, на которых была обучена конкретная модель. Например, базовое разрешение для Stable Diffusion 1.4 / 1.5 составляет 512×512.
Seed. Число, которое используется для генерации исходного шума, с которого начинается создание изображения. Если оставить значение -1, то каждый раз при генерации будут получаться уникальные иллюстрации. А если указать фиксированный Seed и не менять остальные параметры, результат всегда будет повторяться. Это удобно, если вы хотите сохранить понравившийся вариант и воспроизводить его в будущем.
Script. Позволяет запускать дополнительные надстройки поверх основного процесса генерации изображения. Например, скрипт X/Y/Z Plot создаёт сетку изображений с изменяющимися параметрами: числом шагов генерации, алгоритмами, моделями и так далее. Это позволяет быстро сравнить, как разные настройки влияют на итоговое изображение при одинаковом запросе.
 Сетка изображений, созданных с использованием разных моделей генерации по запросу «Portrait of a fantasy warrior, silver armor, cinematic lighting»
Сетка изображений, созданных с использованием разных моделей генерации по запросу «Portrait of a fantasy warrior, silver armor, cinematic lighting»
Советы для получения качественного результата
Рассмотрим несколько базовых рекомендаций, которые помогут оптимизировать процесс генерации изображений.
Начинать можно со значений Steps — около 16, CFG — 7. Это пойдёт для быстрой генерации с базовым уровнем детализации и хорошей привязкой к запросу. Стоит учитывать, что параметры в каждом отдельном случае индивидуальны. Для разных моделей и сэмплеров их лучше подбирать экспериментально, чтобы найти оптимальное сочетание качества и времени рендера.
Если результат генерации не соответствует ожиданиям, выбирайте другие Sampling Methods. Разные сэмплеры будут обрабатывать один и тот же запрос по-разному, а вы сможете выбрать наилучший вариант.
Если на изображении появляются деформации или лишние элементы, попробуйте задействовать Negative Prompt. Но помните, что он не всегда даёт нужный результат, особенно если запрос слишком общий или абстрактный.
При генерации в больших разрешениях (1024×1024 и выше) как правило достаточно 20–30 шагов. Большее значение сильно увеличивает время рендера и может привести к ошибкам.
В качестве альтернативы попробуйте генерировать изображения в нативном разрешении и затем использовать апскейлинг — о нём пойдёт речь дальше.
Как увеличить размер изображения в Stable Diffusion
Хотя размер генерируемого изображения можно задавать вручную, слишком сильное отклонение от нативного разрешения может негативно сказаться на результате. В этом случае помогут апскейлеры — алгоритмы, которые увеличивают изображения с минимальной потерей качества.
Работают они так: сначала иллюстрация генерируется в исходном разрешении, а затем апскейлер увеличивает её и восстанавливает детали. Такой подход позволяет получать изображения, пригодные для печати, крупных макетов или ретуши с максимальной детализацией.
В интерфейсе AUTOMATIC1111 апскейлинг изображения производится следующим образом:
- Загрузите изображение. Перейдите во вкладку Extras и перетащите сгенерированное изображение в специальное поле. Также можно кликнуть на поле и выбрать изображение из папки.
- Выберите апскейлер. Несколько вариантов доступно в AUTOMATIC1111 по умолчанию, но при необходимости можно установить дополнительные. Это позволяет подбирать оптимальный алгоритм под различные требования: от небольшого увеличения до глубокого восстановления текстур.
Для примера можно отметить такие варианты апскейлеров:
1. Lanczos. Простой и быстрый метод. Подходит для небольшого увеличения (1.5x или 2x), но не восстанавливает детали, а лишь масштабирует изображение.
2. R-ESRGAN. Нейросетевой апскейлер, способный восстанавливать мелкие детали и текстуры, в том числе на фотореалистичных изображениях.
3. LDSR. Увеличивает изображение и одновременно дорисовывает недостающие детали. Может быть полезен для стилизованных или сложных иллюстраций, но работает довольно медленно.
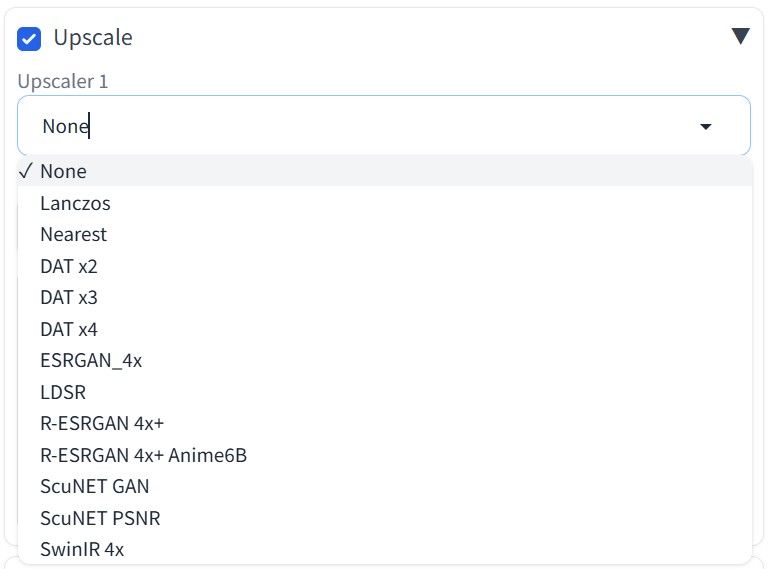 Пример списка апскейлеров в интерфейсе
Пример списка апскейлеров в интерфейсе
- Укажите кратность увеличения. В настройках задайте масштаб (например, 2x или 4x) и запустите процесс. После этого вы получите изображение в более высоком разрешении, готовое для дальнейшей обработки.
 Пример масштабирования изображения в 2 раза с использованием R-ESRGAN 4x+
Пример масштабирования изображения в 2 раза с использованием R-ESRGAN 4x+
А если у вас нет желания разбираться с установкой и настройкой AUTOMATIC1111 или Amuse, попробуйте генерацию изображений прямо в конструкторе Pixcraft. Для этого добавьте в шаблон примитив «Изображение», кликните по кнопке «Нажмите для загрузки» и выберите «AI».
Достаточно описать, что вы хотите увидеть, задать пропорции и при желании выбрать стиль из списка: уже через несколько секунд готовое изображение можно добавлять в письмо. Это быстрее и проще, чем запускать Stable Diffusion вручную.
 Генерация изображения в Pixcraft
Генерация изображения в Pixcraft
Заключение
Stable Diffusion требует ресурсов и внимания к деталям, но открывает гораздо больше возможностей по сравнению с облачными сервисами. Если уделить время настройке и тестированию, вы получите не просто ИИ-генератор, а полноценный инструмент с адаптацией под самые разные задачи.
Экспериментируйте с подходами, пробуйте различные модели и сэмплеры, настраивайте каждый параметр и оценивайте результаты. Всё это позволит быстрее освоиться в инструменте и раскрыть потенциал Stable Diffusion на 100%.